so I spent last several days making collecting watch time on both videos and livestreams more robust and work across multiple peertube instances, im sure it still has gaps in the structure so that jenk data can get in.
if you want to try it heres the link https://github.com/solidheron/peertube_recomendation_algorythm/ btw its a browser extension
so now I got two parts left that I know of first being creating the user_recomendation_vector and the function that gets recommendation based on that vector. I settle on cosine similarity vector since its easy to implement and can be run in browser with only data collected by the user device, and doesnt requires sharing outside of peertube api. user_recomendation_vector should have two part AOLR: (algorithm of last resort) which will be the words in the title, tags, and description tokenized with an float value and recomended_standard: which will be based on what category either programs or people decide a video belongs to along with an associated float value to make it a vector.
I do have issues with deciding if engagement is important, if short video should have multiplier if they’re completed, how much is a like worth, how important is it to get an end of the video.
I should add that I have made complimentary video_description_vector thats store in browser all vector dimentions are 1.
You must log in or register to comment.
What is the repo license?
MIT
Was bored and was doing UI coding :D
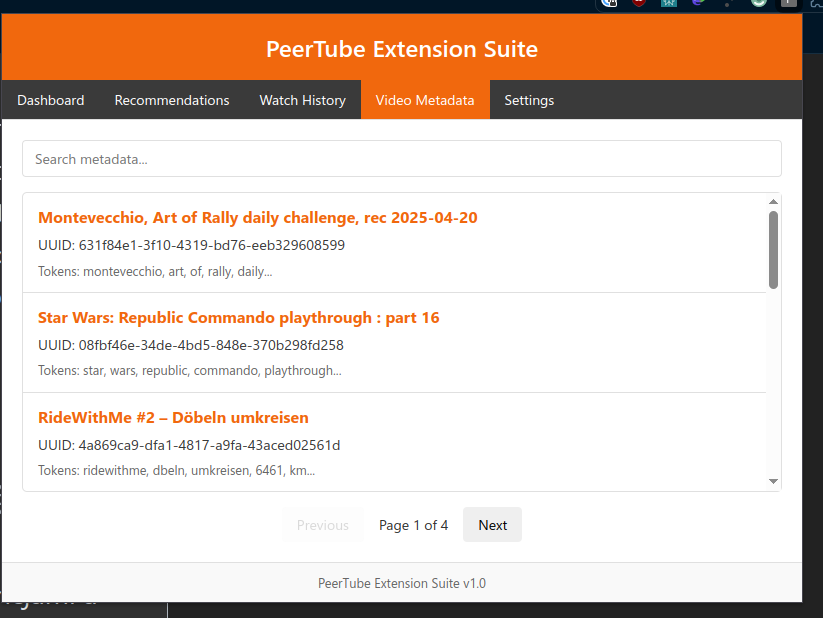
sweet i do need ui to display the recommendations once i get there
Just tossing an idea out there: what about making the algorithm adjustable by the user? I assume there’s differences in which iteration of the Youtube algorithm are preferred by people
yeah no algorithm are a big thing. I’m trying to figure out a simple algo right now so it can light weight. one guy did suggest a slider for things you do and don’t want suggested. I did point this out in another post that there wont be 1 algorithm theres gonna be different kinda of algorythm (on the fediverse), i can see that theres gonna be user collected, user run algo then theres gonna be algo where people share their data and some central server will send suggestions to individual based on that data(because there are people that are okay with sharing their data).
I’m trying to push “collect your own data, run your own algorithms” as a tenant of the fediverse.
